I. Description of the Data Sets
This is a new image-based handwritten historical digit dataset named ARDIS (Arkiv Digital Sweden). The images in ARDIS dataset are extracted from 15.000 Swedish church records which were written by different priests with various handwriting styles in the nineteenth and twentieth centuries. The constructed dataset consists of three single digit datasets and one digit strings dataset. The digit strings dataset includes 10.000 samples in Red-Green-Blue (RGB) color space, whereas, the other datasets contain 7.600 single digit images in different color spaces. Figure 1 illustrates handwritten digit images from different datasets in ARDIS.
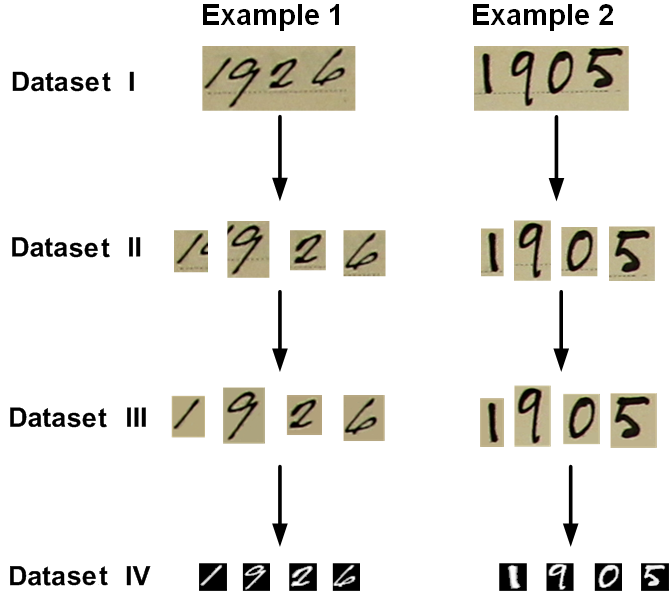
Figure 1. Examples of handwritten digit images from the different datasets in ARDIS.
II. Use of the Materials
The users of the ARDIS Data Set must agree that:
- The use of the data set is restricted to research purpose only
- No redistribution of the dataset is allowed
- In any resultant publications of research that uses the dataset, due credits will be provided to:
Huseyin Kusetogullari, Amir Yavariabdi, Abbas Cheddad, Håkan Grahn and Johan Hall, 2019, "ARDIS: A Swedish Historical Handwritten Digit Dataset," Neural Computing and Applications, Springer.
DOI: 10.1007/s00521-019-04163-3
Link to the paper, Click here
III. Download Links
#### ARDIS DATASET_I: This dataset has been updated 2020-04-04
This date string image data set contains 10000 images of four digit characters and is divided into the following three parts cropped automatically from the original full document images (
more info here >> Readme.pdf <<) :
- Part I: This set contains 3977 RGB images in JPG format.
- Part II: This set contains 4503 RGB images in JPG format.
- Part III: This set contains 1520 RGB images in JPG format.
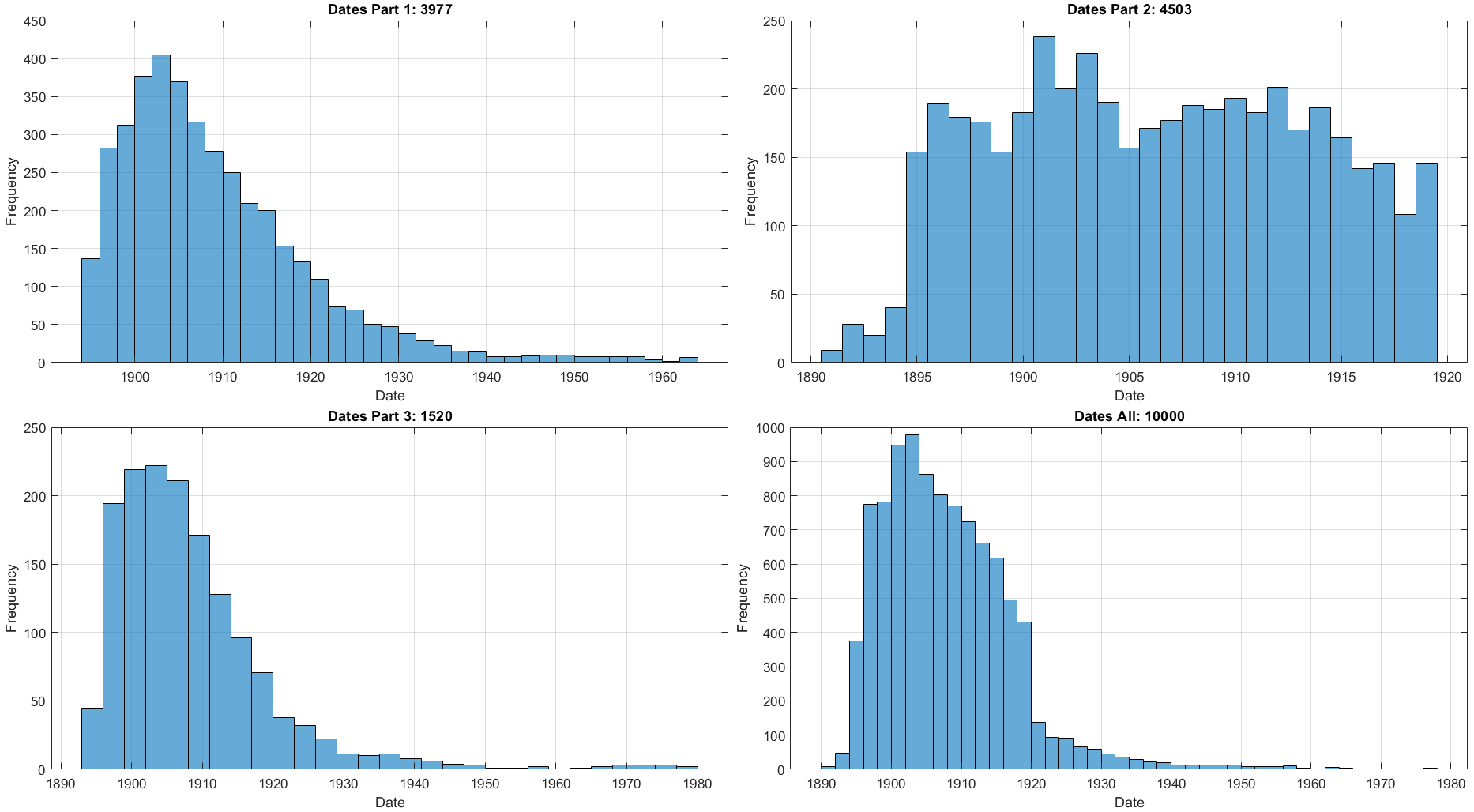
Figure 2. Date Distribution.
#### ARDIS DATASET_II:
This dataset contains 7600 corrupted and noisy handwritten digit images. You can use 6600 images for training and 1000 for testing.
ARDIS_DATASET_II download link: Click here

Figure 3. Corrupted Handwritten Digit Images.
#### ARDIS DATASET_III:
This dataset contains 7600 handwritten digit images with clean background. You can use 6600 images for training and 1000 for testing.
ARDIS_DATASET_III download link: Click here

Figure 4. Handwritten Digit Images.
#### ARDIS DATASET_IV:
This dataset contains 6600 training and 1000 testing images in .csv files. The digit images in this dataset are same format with the MNIST and the USPS digit image datasets.
The results of different machine learning methods in our accepted paper show that the ARDIS dataset is different than the MNIST and the USPS datasets.
- ARDIS_train_2828.csv
- ARDIS_train_labels.csv
- ARDIS_test_2828.csv
- ARDIS_test_labels.csv
ARDIS_DATASET_IV download link: Click here

Figure 5. Illustration of digit values from 0 to 9: a) ARDIS, b) MNIST, and c) USPS
IV. Implementation
#### DATASET_IV
#### In Python
x_train=np.loadtxt('.../ARDIS_train_2828.csv', dtype='float')
x_test=np.loadtxt('.../ARDIS_test_2828.csv', dtype='float')
y_train=np.loadtxt('.../ARDIS_train_labels.csv', dtype='float')
y_test=np.loadtxt('.../ARDIS_test_labels.csv', dtype='float')
#### reshape to be [samples][pixels][width][height]
x_train = x_train.reshape(x_train.shape[0], 1, 28, 28).astype('float32')
x_test = x_test.reshape(x_test.shape[0], 1, 28, 28).astype('float32')
V. Contributions from other Researchers to ARDIS
- Brazil: Bounding box annotations (BBA) using Darknet-YOLO
This set contains the BBA of the ARDIS DATASET_I (10K 4 digits string) Click here .
If you use this annotation & ARDIS in your research, please credit the authors by citing:
For the BBA: Hochuli, A. G.; Britto JR, A. S. ; J. P. Barddal; Oliveira, L.S. ; Sabourin, R. "An End-To-End Approach for Recognition of Modern and Historical Handwritten Numeral Strings,"
In: IEEE International Joint Conference on Neural Networks, 2020.
For ARDIS: Kusetogullari, H.; Yavariabdi, A.; Cheddad, A.; Grahn, H.; Hall, J. "ARDIS: A Swedish Historical Handwritten Digit Dataset,"
Neural Computing and Applications, 2019, Springer. DOI: 10.1007/s00521-019-04163-3.
How to interpret the annotation file?

VI. Feedback or Comments
We will be pleased to get your feedback/suggestions to improve the dataset.

P.S: Interested in whole page historical handwritten documents? Click here for our SHIBR (the Swedish Historical Birth Records) dataset. It is a semi-annotated dataset.
Karlskrona, Sweden on: 2019-04-02
Blekinge Institute of Technology

